If you want to build a faster car, you'll need to learn about aerodynamics and engine design. To write a great song, you'll need to learn about music theory and songwriting techniques.
The same theory holds when building AI models. If you want your AI to reach its goals faster using fewer resources, you'll need to learn as much as possible about automatization options for the ML pipeline, including automated data labeling strategies.
Whether you are a seasoned expert or a curious newcomer, this blog post will provide you with the information you need to understand and use automated data labeling techniques in the most efficient way possible.
What is automated data labeling?
Automated data labeling is a process that uses machine learning (ML) algorithms, automation techniques, or simple rules to create data annotations automatically or with minimal human intervention.
Its main goal is improving efficiency and accuracy while tapping into human expertise when needed.
We view automated data labeling in four layers, each offering different features and considerations to enhance the labeling process.
The four layers of automated labeling are
In this blog post, we'll offer you valuable insight into each layer so you can streamline AI development and reach your AI goals faster.
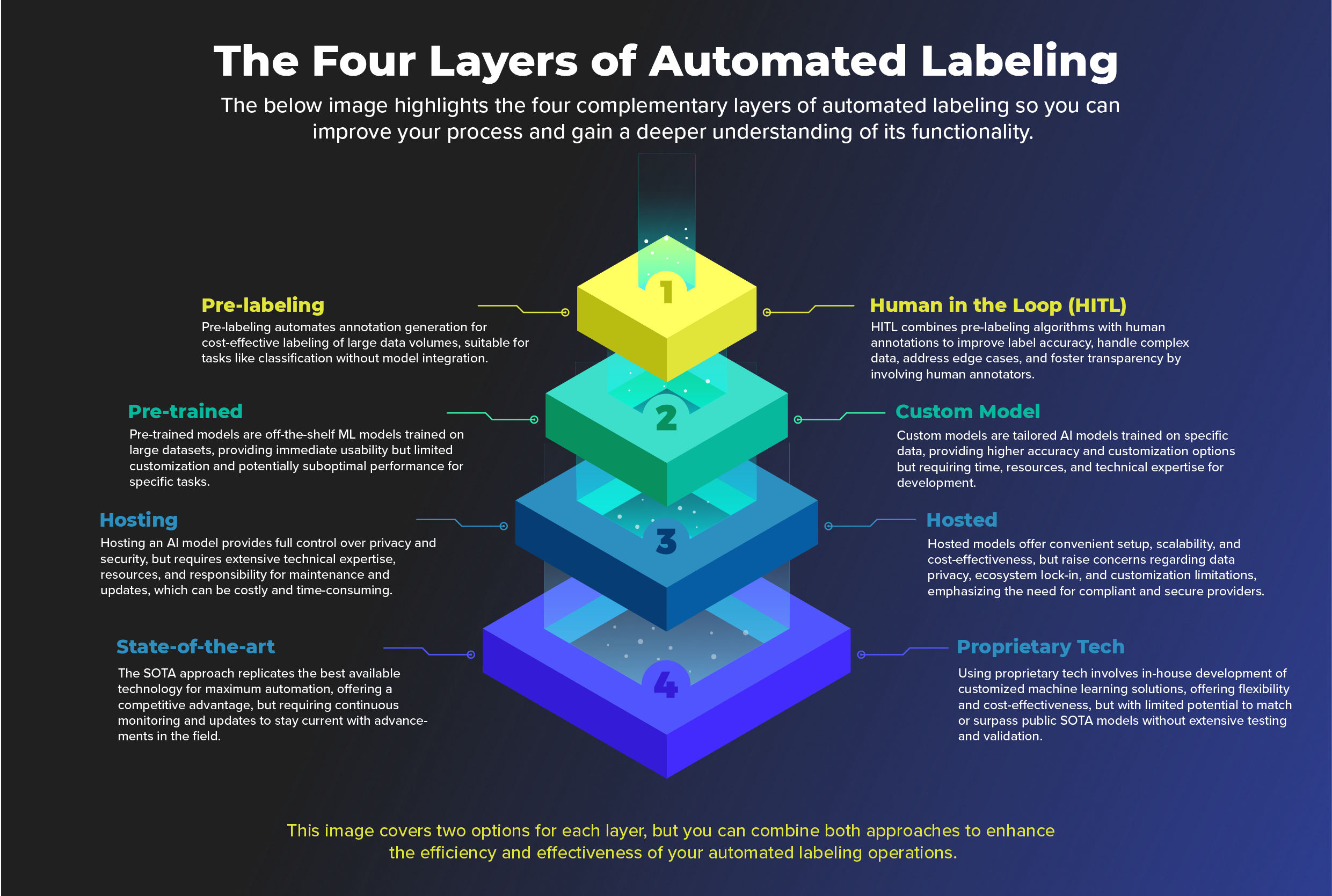
CloudFactory believes that automated data labeling can be enhanced by stratifying it into 4 layers, highlighting the diverse features and considerations available at each level so you can improve the efficiency and accuracy of your AI models.
Layer 1: Pre-labeling vs. HITL
Pre-labeling:
Pre-labeling is an efficient and cost-effective way to annotate large data volumes. It automates the labeling process without the need for human intervention. However, its accuracy relies heavily on the original model's quality, potentially leading to less reliable results. It is best suited for straightforward tasks like traditional classification but may not be ideal for complex labeling requiring human intuition and expertise.
Human in the Loop (HITL):
HITL combines automated pre-labeling with human expert annotations. This approach improves label accuracy, especially for complex and ambiguous data. It also addresses edge cases that automated methods struggle with, fostering transparency and trust in the model. The downside is that it demands more time, resources, and human input, and integration into the labeling pipeline can be costly and time-consuming.
Ultimately, the choice between pre-labeling and HITL depends on project requirements and available resources. Consider whether your annotation tool specializes in one approach or combines both.
Layer 2: Pre-trained Model vs. Custom Model
When choosing between pre-trained and custom ML models for automated labeling, there are some considerations to remember.
Pre-trained Models:
These are ready-made from third parties, making them a quick and accessible option, especially for resource-constrained teams. They cover various tasks like object detection, natural language processing, and image recognition. However, they lack customization, limiting their adaptability during the annotation process. Finding a perfect fit for your specific use case is unlikely, leading to potential underperformance.
Custom Models:
For a tailored solution that matches your needs, a custom model is the way to go. By training the model on relevant data, you can achieve higher accuracy and performance. Custom models provide more flexibility and customization options but require time, resources, and technical expertise for development, delaying the main task until the model is ready.
Ultimately, your choice should be based on your project's requirements, available resources, and the level of customization needed for optimal results.
Layer 3: Hosting vs. Hosted AI Model
Hosting an AI Model:
If you host an AI model yourself, you'll have complete control over privacy and security without worrying about ecosystem lock-in. But, hosting yourself requires significant technical expertise and resources, making it costly and time-consuming to maintain.
Third-party Hosted AI Model:
Opting for a hosted model by a third party, like an annotation service provider, reduces setup obstacles and offers scalability without infrastructure limitations. It's a more cost-effective option, but consider potential data privacy and security concerns, as well as customization limitations or ecosystem lock-in. Choose collaborative providers adhering to HIPAA, GDPR, and ISO 27001 standards for peace of mind.
Layer 4: State of the Art (SOTA) vs. Proprietary Tech
State of the Art (SOTA):
Replicating the best publicly available technology is a great way to achieve maximum automation and gain a competitive advantage. It ensures you're using the most modern and effective approach tested and benchmarked by researchers. However, staying up-to-date with advancements and updates can be time-consuming and costly.
Proprietary Tech:
Developing in-house ML solutions tailored to your task allows for more customization without being limited by rules. It tends to be cost-effective and requires less technical expertise. However, matching or outperforming public SOTA models is unlikely for most use cases, as only a few organizations have the resources to produce better proprietary technology.
How CloudFactory approaches each layer of automated data labeling
At CloudFactory, we combine pre-labeling and human-in-the-loop techniques for layer one. Our clients can opt for a full human-in-the-loop strategy or use pre-labeled data for QA purposes.
We utilize pre-trained starter models for layer two, fine-tuning them with client-specific data for a customized labeling experience.
For layer three, we employ a hosted model approach prioritizing data security with HIPAA compliance, GDPR adherence, and ISO 27001 standards. Clients aren't locked into our ecosystem and can export models at any stage.
For the fourth layer, we provide clients with the most advanced and effective SOTA solutions, giving ML teams a competitive edge without requiring extensive investments in time and resources. CloudFactory's Accelerated Annotation solution offers 5x faster labeling speed and is powered by adaptive AI assistance, critical insights, deep expertise, and a proven workflow.
If you're building your annotation strategy and need greater detail about these decision points, download our comprehensive white paper, Accelerating Data Labeling: A Comprehensive Review of Automated Techniques. You won't be disappointed.
You'll also get a detailed overview of the top computer vision model building, annotation acceleration, and automated labeling approaches, including self-supervised and active learning, so you can enhance the efficiency and accuracy of your automation processes.







