As a CV or ML engineer, data labeling is likely one of your biggest headaches.
You're tasked with looking for ways to accelerate your project timeline and deliver high-performance models faster. This usually means diligently researching a myriad of data labeling solutions.
The pain and expense of manually labeling large datasets can significantly slow project progress and leave ML teams wondering what they signed up for when they accepted the job.
But what if there was a way to make data labeling less painful and expedite active learning in ML projects up to 5x faster?
You can if you deliberately create a data annotation strategy that incorporates the power of active learning in machine learning.
What is active learning in machine learning?
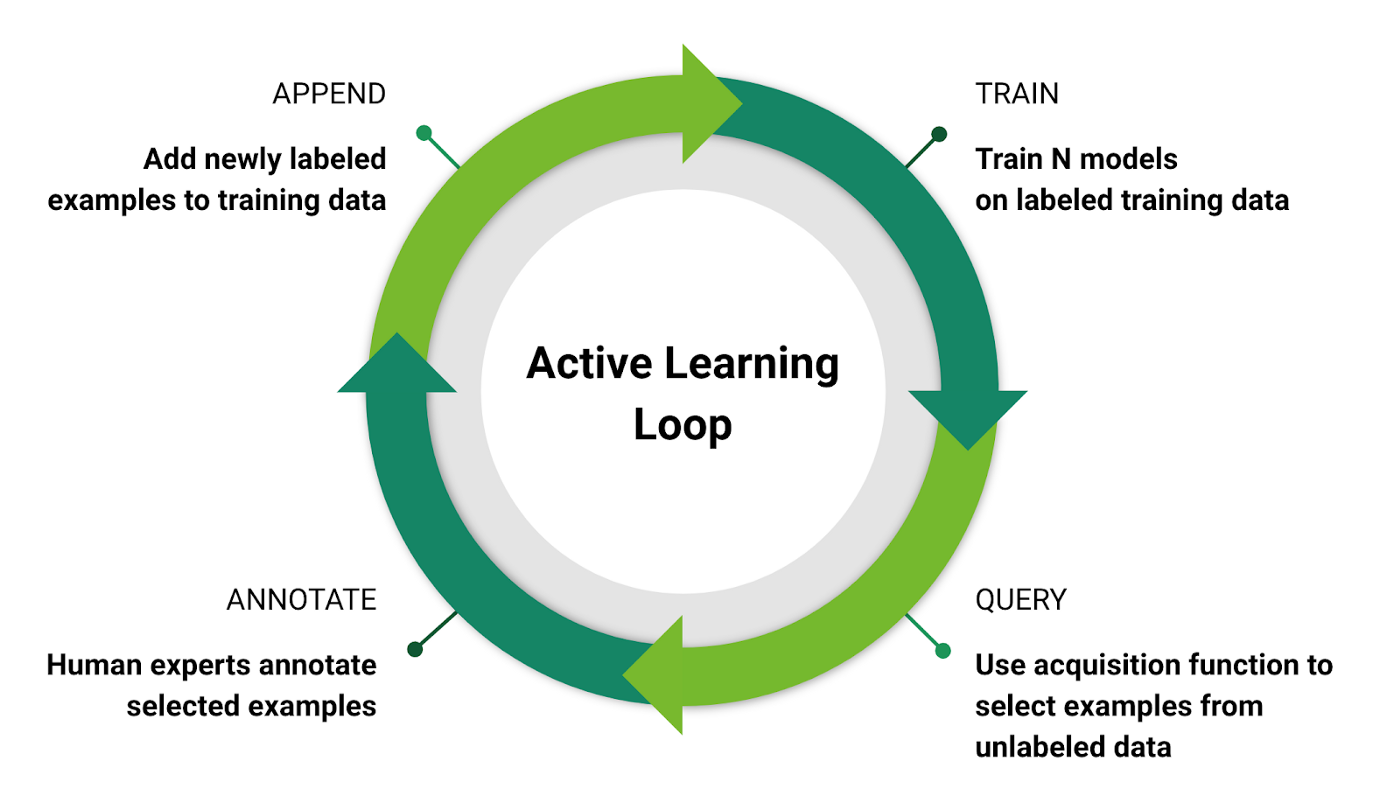
Active learning in ML is a method that uses a step-by-step process to identify the most valuable and informative data in a project, suggesting it is a priority for labeling by human data annotators.
To do this, the algorithm determines the uncertainty level it has about particular image labels. The more uncertain it is, the more valuable and informative the image is considered, and it receives a higher rank.
By labeling the high-ranking images first, you can significantly improve the performance of your model (enhance the metric value - for example, the Intersection over Union one) and speed up the development process. This approach ensures that the model focuses on the most crucial and uncertain areas, helping it learn more effectively and efficiently.
Source: Scalable Active Learning for Autonomous Driving: A Practical Implementation and A/B Test, NVIDIA AI
The annotation process using active learning in machine learning follows a basic algorithm consisting of the following steps:

The image above shows how active learning is used to annotate data step-by-step.
Why should you use active learning for computer vision projects?
1. You'll save money.
Using active learning techniques significantly reduces annotation costs by requiring fewer labeled images to achieve comparable model performance compared to traditional annotation methods.
2. You'll increase quality.
With active learning in ML, models learn from the most informative samples, enhancing accuracy and generalization.
According to Techcrunch, sophisticated companies should be ready to leverage active learning machine learning as it's fundamental for closing the prototype-production gap and increasing model reliability.
It’s a common mistake to think of AI systems as a static piece of software, but these systems must be constantly learning and evolving. If not, they make the same mistakes repeatedly, or, when they’re released in the wild, they encounter new scenarios, make new mistakes, and don’t have an opportunity to learn from them.
3. You'll gain efficiency.
Active learning ML can remove the dependency on a large labeled dataset by actively choosing samples likely to impact the model's performance. And it can also be applied to any computer vision task.
4. You'll boost scalability.
When building your ML solution foundation, you must prepare for scale. As your model scales, you'll find more and more edge cases. Using these edge cases to upgrade your model using active learning ML is wise. This way, you will build a train-and-sustain strategy instead of a deploy-and-hope strategy.
CloudFactory's approach to active learning for computer vision projects
In the constantly evolving landscape of computer vision model building, annotation acceleration, and automated labeling, CloudFactory is at the forefront by incorporating the latest technology advancements with a global data labeling workforce. We’ve integrated the best parts of active learning ML into Accelerated Annotation, our best-in-class data labeling and workflow solution.
Our approach employs active learning with uncertainty sampling to label the most informative instances, leveraging the model's uncertainty to optimize the process. Doing so saves valuable time for our clients and allocates our workforce to high-value tasks, which enhances your ROI.
If you're building your data annotation strategy and need greater detail about Vision AI decision points, download our comprehensive white paper, Accelerating Data Labeling: A Comprehensive Review of Automated Techniques.







