This blog post was originally published by Hasty.ai on January 17, 2022. Hasty.ai became a CloudFactory company in September 2022.
If you have ever worked with an ML model in a production environment, you might have heard of MLOps. The term explains the concept of optimizing the ML lifecycle by bridging the gaps between design, model development, and operation processes.
Today, MLOps is not just a concept but a much-discussed aspect of machine learning that is growing in importance as more and more teams work on implementing AI solutions for real-world use cases. If done right, it helps teams all around the globe to develop and deploy ML solutions much faster.
MLOps is often referred to as DevOps for machine learning. That’s why the easiest way to understand the MLOps concept is to return to its origins and draw a parallel between it and DevOps.
Let’s jump in.
What is DevOps?
Development Operations (DevOps) is a set of practices that combines software development, testing, and IT operations. DevOps aims to turn these separate processes into a continuous pipeline of interconnected steps. So, if you follow the DevOps philosophy, you will shorten the systems development life cycle and provide continuous delivery with high software quality.
The core principles of DevOps are process automation, feedback loops, and the CI/CD concept.
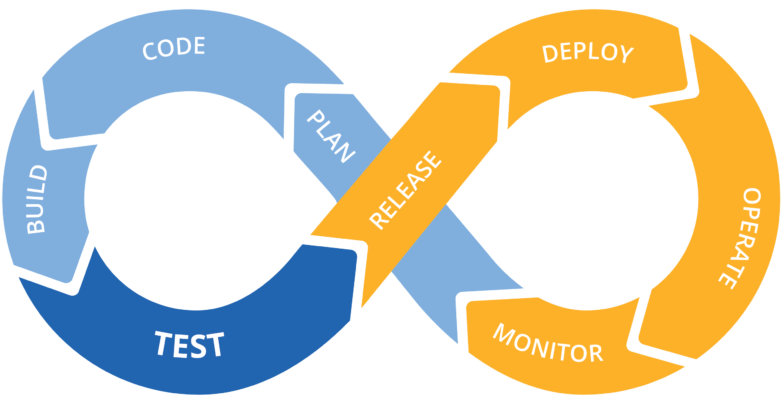
In software engineering, the CI/CD loop refers to the combined practices of continuous integration (CI), continuous delivery (CD), and continuous deployment.
-
Continuous Integration (CI)
CI is the practice of automating code changes from multiple contributors into a single software project, ultimately optimizing the code changes. -
Continuous Delivery (CD)
CD provides automated and consistent code delivery to various environments, for example, testing or development. When the newest iteration of the code is delivered and passes the automated tests, it is time for continuous deployment that automatically deploys the updated version into production.
To simplify, CI is a set of practices performed during the coding stage, whereas CD practices are applied whenever the code is ready.
So, the CI/CD loop combines software development, testing, and deployment processes into one workflow. It heavily relies on automation and aims to accelerate software development. With CI/CD, development teams can quickly deploy minor edits or features. This makes it possible for teams to develop software in quick iterations while keeping its quality.
In addition, since programmers can spend less time manually coding, deploying changes, and doing other routine tasks, they can focus more on the customers’ requests to update functionality or create new features. With DevOps, when working in short cycles, your users will not have to wait long for some big release to get an upgraded version of an application.
To summarize, with DevOps, you will be able to improve communication and collaboration between your development and operation teams to increase the speed and quality of software development and deployment.
Got it. Now...
What is MLOps?
Today, ML model development and operations are often entirely separate, and the deployment process is manual. Therefore, building and maintaining a solution might take longer than expected. Machine Learning (ML) Operations (Ops) is a set of techniques used to optimize the entire ML lifecycle. Like DevOps, its aim is to bridge the gaps between design, model development, and operations.
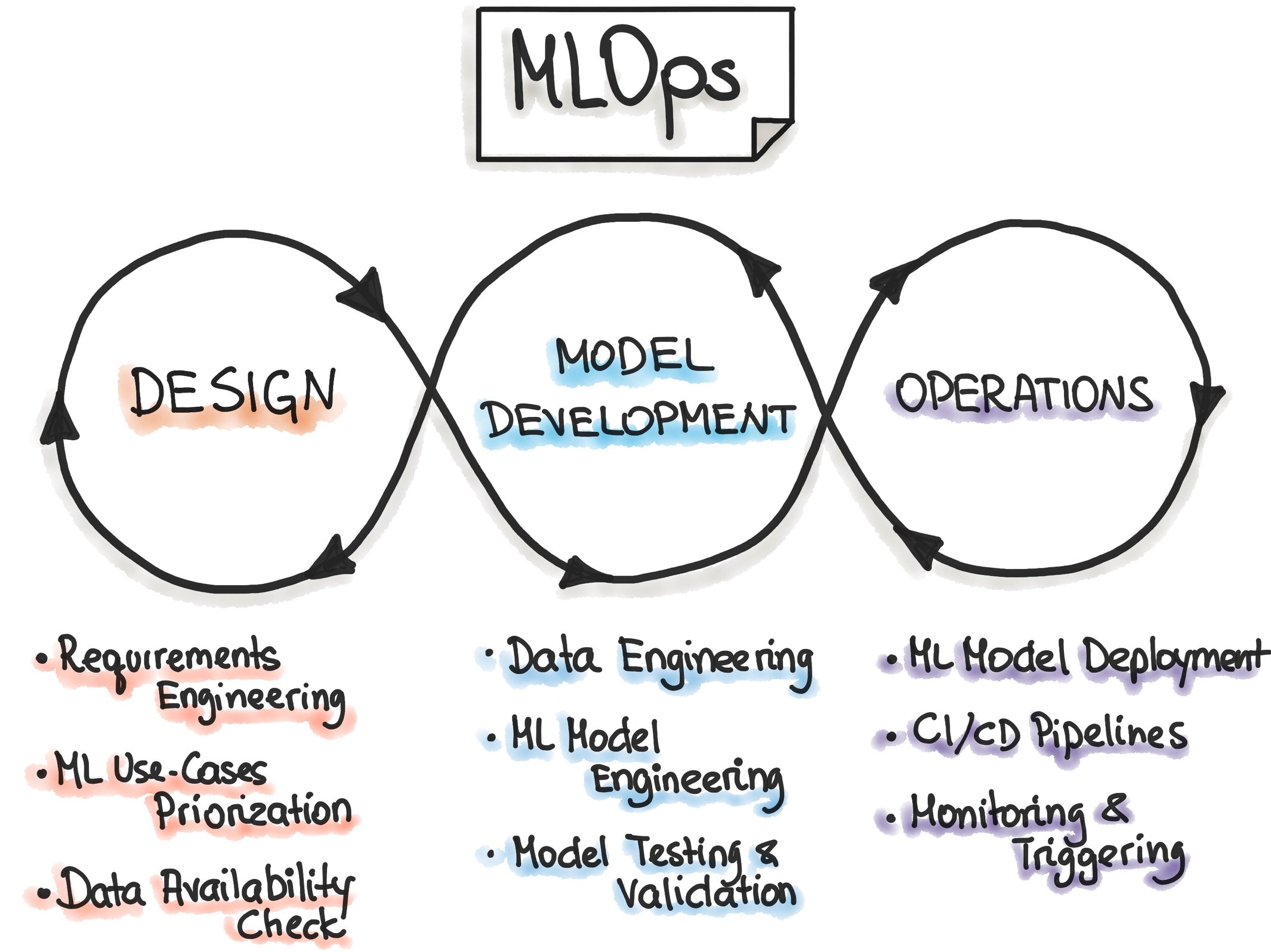
MLOps focuses on combining all the stages of the ML lifecycle into a single process workflow. Such a goal requires collaboration and communication between many departments in a company. However, if you manage to achieve it, MLOps provides a common understanding of how ML solutions are developed and maintained for all stakeholders. It’s similar to what DevOps does for software.
The key MLOps principles are:
- Versioning: Keeping track of the versions of data, ML model, code around it, etc.
- Testing: Testing and validating an ML model to check whether it is working in the development environment
- Automation: Trying to automate as many ML lifecycle processes as possible
- Reproducibility: Attempting to get identical results given the same input
- Deployment: Deploying the model into production
- Monitoring: Checking the model’s performance on real-world data
The core practices of MLOps are continuous integration (CI), continuous delivery (CD), continuous training (CT), and continuous monitoring (CM).
We have already gone through the definition of CI in DevOps above. In MLOps, we essentially do the same. However, in addition to testing and validating the code, CI includes testing and validating data and ML models.
CD works with an ML training pipeline that automatically deploys the model into production. CT is a unique property for ML solutions that is concerned with automatically retraining and serving ML models. Finally, CM is about monitoring production data and measuring model performance using specific metrics (for example, some business metrics or machine learning metrics like hamming score or F-score).
So, the MLOps loop is pretty similar to the DevOps one with slight adjustments that are ML-specific. With MLOps, you can deploy an ML training pipeline that can automate the retraining and deployment of new models, which is more effective than deploying a single model available via an API endpoint. Following the MLOps philosophy when developing an ML solution has many benefits, which we’ll discuss later.
MLOps vs. DevOps: The differences
As you might have noticed, there are a lot of similarities between MLOps and DevOps concepts. It should not be a surprise because MLOps borrows a lot of principles developed for DevOps.
Both DevOps and MLOps concepts encourage and facilitate collaboration between the development teams, for example, programmers, ML engineers, employees who manage the IT infrastructure, and other stakeholders. Also, both aim to automate the continuous development processes to maximize the speed and efficiency of your engineering team.
However, despite DevOps and MLOps sharing similar principles, it is impossible to take DevOps tools and straightforwardly use them to work on an ML project. Unfortunately, the importance is in the details, so MLOps has some ML-specific requirements. Let’s check out the three biggest differences.
1. Versioning differences
The first difference you should keep in mind is how versioning is handled. In DevOps, it is pretty straightforward as you use versioning to provide clear documentation of any changes or adjustments made to the software under development. So, 99,9% of the time, it’s only about the code. That is why in DevOps, we usually refer to versioning as code versioning.
However, when working on an ML project, code is not the only aspect that might change. In addition to the code, MLOps aims to keep an eye on the versions of the data, hyperparameters, logs, and the ML model itself.
2. Computational resources
If you have ever worked on an ML project, you might know that training an ML model requires a lot of computational resources. For most software projects, the solution’s build time is entirely irrelevant, and therefore, the hardware does not play a significant part. Unfortunately, in ML, the situation is the opposite. It might take plenty of time to train larger ML models, even if you use large GPU clusters. That’s why there are more stringent hardware testing and monitoring requirements in MLOps.
3. Monitoring approaches
In software development, the characteristics of your solution might not need any changes over time, whereas in ML, models must change to stay competitive. In ML, once you deploy the model into production, it starts working on the data it receives from the real world. Real-life data is constantly changing and adapting as the business environment changes. So, the quality of the model decreases as time proceeds. MLOps provides automated procedures that facilitate continuous monitoring, model retraining, and deployment to minimize this problem. This helps the model remain up-to-date and keep its performance consistent.
Existing problems with model development
It’s no secret that there are many obstacles you might face when developing, deploying, or operating an ML solution. However, it is always better to know what challenges might await so you can develop a potential solution. Here are a few of the most common problems to be on the lookout for:
-
Lack of automation
Many processes in the ML lifecycle happen manually. Specialists spend lots of time doing relatively simple yet tedious tasks, such as data annotation. The conventional approach to the labeling process is manually labeling each data asset in the dataset. However, the process can be semi-automated using AI-assisted annotation to save time and budget. This pattern is true for many ML lifecycle stages. -
Ineffective solutions
Unfortunately, 87% of machine learning projects do not get into production because they face some unsolvable issues in the development stage. It might happen because of various reasons, but in general, such solutions are simply not good enough to take a shot in production. -
Lack of communication
To build an effective ML solution that will be successful both in development and in production, your development and operations teams must interact with one another and provide the necessary support, guidance, and expertise where needed. Unfortunately, in real-life, these teams are often siloed. -
Changing job duties
Sometimes data scientists are viewed as universal soldiers who can find and label the data, develop an effective ML model, deploy it into production, and provide network security. However, that’s not ideal. Data scientists are not ML engineers, expert annotators, or information security specialists. They should do what they know best — work with the data and develop complex ML models. In any other field, they might lack the necessary knowledge and competence. -
Shifting data
Another problem to watch for is the potential decrease in the model’s accuracy during production due to data shift. This causes problems because the predictions can become less accurate as time passes.
Potential solutions with MLOps
Now that you know the challenges to look for, let’s see how MLOp, allows you to address the most common issues and get some additional benefits.
-
Process automation
Choosing the right MLOps tool will automate some ML lifecycle processes, such as model retraining and deployment. -
Constant communication
MLOps is impossible without getting everyone on the same page and aligning the development and deployment strategies. So, to succeed under the MLOps system, your departments must communicate and collaborate. -
Faster iterations
When working on an ML project in quick iterations, the team is likely to deliver a working product instead of staggering somewhere in the middle lost in the sea of data, model versions, experiments, hypotheses, etc. -
Focused job duties
With the automated deployment process, data scientists will be able to focus on their primary tasks. -
Repeatable training
You can create repeatable training and serving ML pipelines that you can then reuse for other ML projects. -
Improved feedback
Automated processes give developers more time to spend on improving the solution by analyzing and implementing customers’ requests and ideas. -
Reduced data shift
The data shift problem can be solved using the data-centric AI and Data Flywheel approaches complementing the MLOps philosophy.
Get your data production-ready
With only 13% of Vision AI projects making it to production, embracing MLOps is necessary to get raw data into a production-ready model. It’s the key to automating processes, communicating better, and stopping data shifts. CloudFactory can help with those elements, too. Our Accelerated Annotation product is the perfect blend of automation and human expertise to add to your MLOps tool belt.







