
Learn how AI failures like Zillow's $881M loss impact businesses and why robust AI governance must be elevated from IT concerns to CEO strategic priorities.
CloudFactory Blog

Transform healthcare operations with AI analytics converting unstructured data into actionable insights, improving care, reducing costs and staff turnover.
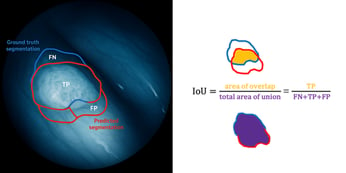
Discover why Intersection over Union (IoU) is essential for precise AI-driven skin cancer detection, reducing false diagnoses and enhancing patient care.

Discover unstructured data’s role in AI, key differences from structured data, and best practices for handling and processing it effectively.

Accuracy alone can mislead in CV. Discover why robust metrics like recall, precision, and IoU are essential for safe, reliable AI.

GenAI implementation challenges, solutions, and success stories. How NLP and CV industry leaders bridge AI innovation to tangible business outcomes.

Discover how effective data curation improves AI insights by organizing, cleaning, and managing high-quality data.
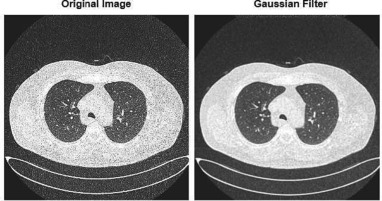
Discover how adding Gaussian noise to medical imaging trains AI to overcome imperfection, enhancing diagnostic accuracy and reliability in healthcare.

Segmentation mask visualization enhances AI model accuracy, improving object detection, medical imaging, and autonomous systems.

Segmentation mask visualization enhances AI model accuracy, improving object detection, medical imaging, and autonomous systems.

The latest AI wave adapts to real-world data, but success demands customization, cultural awareness, and human oversight. Learn how tailored AI drives impact.

Even as the competition fails, strategic partnerships and robust data preparation can transform your AI into scalable, impactful enterprise solutions.

Discover how to achieve sub-100ms ML predictions by optimizing infrastructure, data pipelines, and robust monitoring in this low-latency MLOps guide.

Explore key insights from the AI Action Summit in Paris, including major investments, global collaboration, and regulatory developments shaping AI.

GenAI is booming, but success isn’t about chatbots. Businesses need strong data and strategic AI partners like CloudFactory to drive value.

Discover how Large Language Models (LLMs) transform industries, from software development to finance, creativity, and beyond, with real-world success stories.
